4.5 Determinization
The key to the determinization algorithm is the identification of sets
of nodes on the original graph with single nodes in the resulting deterministic
graph. This is also what causes the exponential computational complexity
as there are 2N sets of nodes in an original graph of
N nodes. Luckily, all sets will not be considered during the construction
of the deterministic graph. Still, the main effort in the implementation
of the algorithm involves the storage of sets of nodes in an efficient
manner.
To simplify the algorithm slightly, we assume that there is exactly one
start node and one end node in the graph. This can easily be enforced in
the case of word-lattices, in particular if all utterances must begin and
end with the special "silence" symbol.
-
The algorithm can now be described as follows:
-
Identify nodes ni of the deterministic graph with sets
of nodes Ni in the original latice.
-
Define N0 to be the set containing only the start node
of the lattice, and Nend to be the set containing only
the end node of the lattice.
-
Initialize the deterministic graph with the node n0.
-
For each node, nx in the deterministic graph and each
word w
Let Ny be the set of nodes in the lattice that can
be reached from a node in Nx with the word w.
If there is no node ny in the deterministic graph - add it.
Add an arc with word w from nx to ny.
The procedure is illustrated in Figure 10.
Computationally, the greatest problem is how to store the sets of nodes
in an efficient manner. It is important to be able to quickly determine
if a set already exists, or if it represents a new node in the deterministic
graph. In the implementation, this was solved by a combination of a hash-table
and comparing sorted sets of nodes. The hash table is based on a hash-key
that is independent of the order of the nodes, and the sets are not sorted
unless necessary. This means that whenever an already existing set is looked
up, it will be necessary to sort it and the lists with the same hash-key
among the already existing. But no sorting is needed to insert a new set
unless a hash-table clash occurs. Because large sets are likely to be looked
up only once, the effect is that larger sets are seldom sorted.
4.6 Minimization
The deterministic graph constructed in the previous section can now be
minimized by considering the partial word sequences that can be generated
forward from each node. We define for any path of arcs from a particular
node to the end-node, the sequence of words on the arcs as generated by
the node forward.
Any pair of nodes that generates exactly the same word-sequences can clearly
be merged without changing the set of complete word-sequences generated
by the graph. The special structure of word-graphs makes this merging particularly
simple. Because all arcs flow from left to right, the nodes are processed
from right to left. It is then guaranteed that when processing a particular
node, all nodes to the right of it that can be merged, are in fact already
merged. Therefore, all nodes to the right of the current node generate
different sets of sequences forward.
The notion of "left" and "right" can be formalized by introducing maximum
and minimum depth. This is the length of the shortest and the longest word
sequence generated from the node (see Figure 11).
Only nodes that have exactly the same maximum and minimum depth need to
be considered for merging. Further, if nodes are processed in order of
increasing minimum depth, all that needs to be compared is the words on
the out-flowing arcs and the node that they flow to. There is no need to
consider more than one arc forward because all nodes forward generate different
word-sequences. The procedure of merging nodes is illustrated in
Figure 12 where the deterministic graph constructed
in Figure 10 is continued with the minimization
step.
In general, the minimization step has N log(N) computational complexity.
However, because of the directed acyclic structure of word-graphs and the
distribution of word duration, the number of nodes with identical maximum
and minimum depth is approximately a linear function of utterance length.
4.7 Computational considerations
As noted earlier, the determinization procedure has, in the worst case,
exponential computational complexity with respect to the number of nodes.
However, the input lattice-size has at least two distinguishable dimensions:
the utterance-length and the graph-density (number of arcs per utterance-length)
(Ney and Aubert, 1994). Graph-density corresponds to the amount of pruning
and utterance-length corresponds to the length of the input. Of the two,
the length of the input is varying, but the amount of pruning can be controlled
in the A* search.
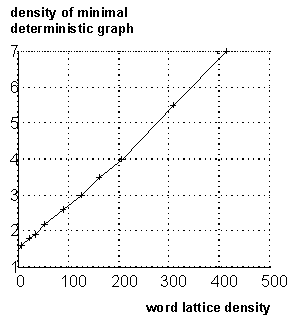
We studied empirically the time-complexity of the construction of the DFA
in the 1000-word spontaneous speech task of the WAXHOLM-project (Blomberg
et al., 1993; Paper 3). In the top graph of Figure
13 the exponential behavior can be seen, but the bottom graph shows
approximately linear time-dependence with respect to utterance-length when
the dependency of the graph-density have been eliminated. This difference
in behavior for the two dimensions is very important because it gives us
the possibility to control the "exponential explosion" of the algorithm
by tuning the pruning.
For comparison, the word-pair approximation was also investigated.
Applying the word-pair approximation to the word-lattice resulted on average
in a reduction in the number of arcs to 8.1% of the original lattice. The
minimal deterministic graph for the same word-lattice was on average reduced
to 1.4% of the lattice.
4.8 Discussion
The exact minimization algorithm investigated in this study was clearly
shown to produce smaller graphs than the approximate word-pair approximation
method. This is true in spite of the fact that the exact algorithm minimizes
the number of nodes, but the two methods are compared on the basis of the
number of arcs. In the example investigated, the exact algorithm produced
almost six times smaller graphs than the approximate method, but the exact
quotient is likely to be dependent on the lexicon, pruning aggressiveness
etc.
In contrast to the word-pair approximation, the graph of the proposed algorithm
generates exactly the same word-strings as the original lattice (no hypotheses
are lost by approximation). However, since the proposed method is exponential
with respect to lattice-density, a hybrid-approach where the lattice is
first reduced by the word-pair approximation and then minimized, seems
to be an attractive alternative.
The computational demands of the exact minimization are probably too
high for use in the on-line recognition mode of a real-time ASR system
(with contemporary computer technology). However, for off-line tasks, where
the same minimized word-graphs are used repeatedly, the effort may be worthwhile.
Iterative estimation of grammar parameters during training of the system
is one example. |
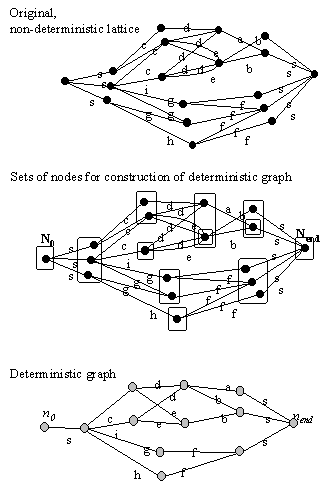 Figure 10. Illustration
of the determinization algorithm. The set N0 is the first
to be taken care of in step 4, and there is only words labeled "s" flowing
out from it so w=s. The set of nodes reached by the s-arcs is the
next node of the deterministic graph. This set in turn has four different
words flowing out from it (c, i, g, h), and four corresonding new sets
are formed. The process continues until no new sets are formed.
Figure 10. Illustration
of the determinization algorithm. The set N0 is the first
to be taken care of in step 4, and there is only words labeled "s" flowing
out from it so w=s. The set of nodes reached by the s-arcs is the
next node of the deterministic graph. This set in turn has four different
words flowing out from it (c, i, g, h), and four corresonding new sets
are formed. The process continues until no new sets are formed.
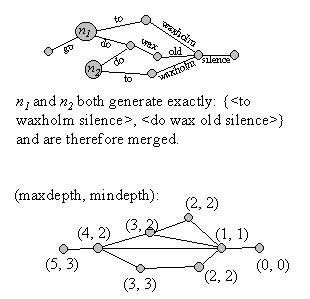
Figure 11. Illustration
of the minimization. For each pair of nodes it is checked if they generate
exactly the same set of partial word-sequences forward. Because word-graphs
are acyclic, it is possible to efficiently compute the longest and shortest
generated word-sequences generated forward from each node (max and min
depth). This reduces the number of node-pairs to compare significantly
because only those with the same maximum and minimum depth need to be considered.
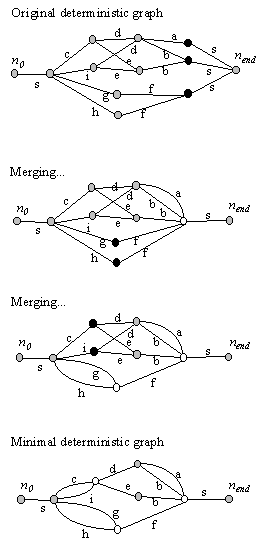 Figure 12. Illustration
of the merging of nodes in the minimization step of the algorithm. Merging
proceeds from right to left and because all nodes to the right are merged
if possible, it is easy to check if two nodes generate the same word sequences
forward. See the main text for details.
Figure 12. Illustration
of the merging of nodes in the minimization step of the algorithm. Merging
proceeds from right to left and because all nodes to the right are merged
if possible, it is easy to check if two nodes generate the same word sequences
forward. See the main text for details.
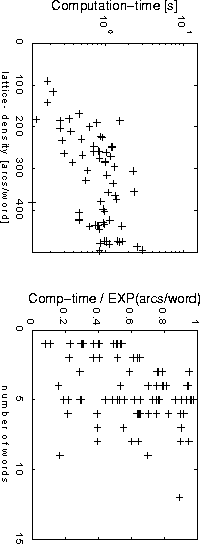
Figure 13. Top:
Time for construction of the DFA as a function of the lattice-density.
Bottom: Construction time divided by the exponential of the lattice density.
The simulation was made on a SPARC 10 workstation. This figure is taken
from Ström (1995). |